


Retrieve and browse your YouTube and YouTube Music history from Google Takeout
With Pandas and Beautifulsoup in Python


In this post, I go through the steps to download my own YouTube and YouTube watch & search history from Google Takeout. Details of the Google Takeout are available from...
%[spanning.com/blog/google-takeout-is-it-a-go..
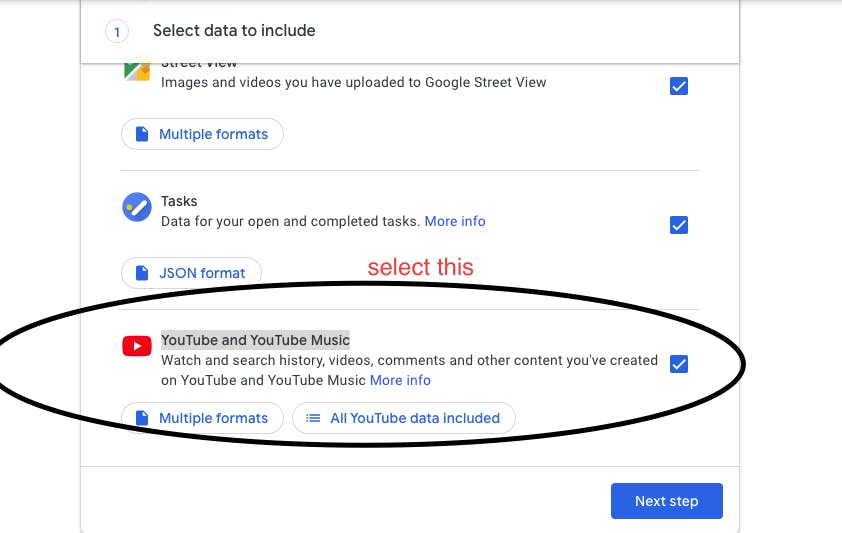
Download the data
I downloaded my YouTube and YouTube Music record
The main data I am going to deal with is the watch-history.html file.
Of course, you can get a good idea of your browsing activity. In my case, I deeply regret that I wasted time watching crappy videos...なんてこった!
However, you ain't analyze and visualize your YouTube behavior just by looking at the HTML file. So, scraping the data to the manageable format (CSV).
Once you find the file, start writing Python code to scrape the information from this file.
Modules I am going to use for this post are
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup as bs
import re
from datetime import datetime
import json
import pandas as pd
Then, scrape through the HTML file.
try:
del(frame)
except NameError:
baseURL="path-to-your/history/watch-history.html"#specify url for each page
# page=requests.get(baseURL)# reuqest the url contents
soup = bs(open(baseURL), 'html.parser')# parse html structure
for content in soup.find_all("div",{'class':'mdl-typography--body-1'}):
if len(content.contents)<6:
pass
else:
vurl=re.findall('(?<=<a href=\")(.*?)\">',str(content.contents[1]))
vtitle=re.findall('(?<=\">)(.*?)</a>',str(content.contents[1]))
curl=re.findall('(?<=<a href=\")(.*?)\">',str(content.contents[3]))
ctitle=re.findall('(?<=\">)(.*?)</a>',str(content.contents[3]))
date=content.contents[5]
if len(curl)<1:
curl=["NA"]
if len(ctitle)<1:
ctitle=["NA"]
if len(vurl)<1:
vurl=["NA"]
if len(vtitle)<1:
vtitle=["NA"]
if len(date)<1:
date=["NA"]
d=[{"Date":date,"VideoURL":vurl[0],"VideoTitle":vtitle[0],"ChannelURL":curl[0],"ChannelTitle":ctitle[0]}]
try:
frame=frame.append(pd.DataFrame(data=d))
except NameError:
frame=pd.DataFrame(data=d)
print(date)
soup = bs(open(baseURL), 'html.parser')
is the code to parse html structure. soup object is simply a text.
for content in soup.find_all("div",{'class':'mdl-typography--body-1'}):
after inspecting the code block, I found that the video title, video link, channel title, channel link, and date are in mdl-typography--body-1 class. Thus I acquired all the strings in the specified tag and class.
vurl=re.findall('(?<=<a href=\")(.*?)\">',str(content.contents[1]))
is a regular expression search that finds all the strings satisfy the condition that the strings are between a href=\" and \">. The rest of the regular expression codes are the same as the first one.
Some of the watch histories do not include any information. In that case, I assign NA to each part of the information.
A data frame is created from each watch history. By stacking the individual watch history, I finally obtain the data frame of which rows represent the single watch history.

From here, I am going to analyze my YouTube browsing history also known as Pandora's box.
最後まで読んでくださりありがとうございました!